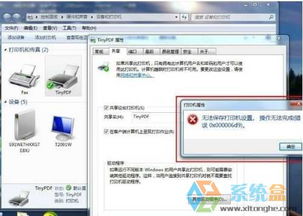
在使用Windows 7操作系統(tǒng)進行打印機共享時,許多用戶可能會遇到錯誤代碼0x000006d9,提示信息通常為“操作無法完成”。這個錯誤主要與系統(tǒng)服務未正確啟動或配置有關。本文將詳細介紹此錯誤的成因,并提供一套清晰、可操作的解決方案,幫助您快速恢復打印機共享功能。
錯誤0x000006d9的核心原因
該錯誤的根本原因通常是負責Windows防火墻相關設置的Windows防火墻服務(Windows Firewall) 被禁用或未運行。打印機共享功能依賴于該服務來管理網(wǎng)絡端口的例外規(guī)則。當服務未啟動時,系統(tǒng)無法為共享打印機創(chuàng)建必要的防火墻規(guī)則,從而導致共享失敗。
解決步驟詳解
請按照以下順序逐步操作:
第一步:啟動Windows防火墻服務
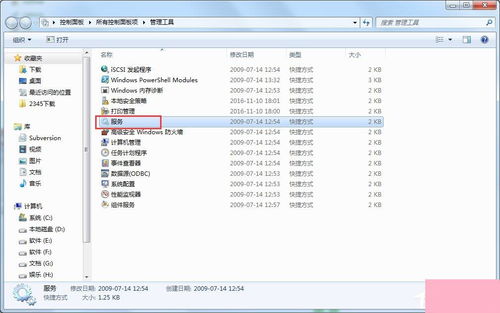
- 點擊屏幕左下角的 “開始” 按鈕,在搜索框中輸入 “services.msc” ,然后按回車鍵,打開“服務”管理控制臺。
- 在服務列表中找到名為 “Windows Firewall” 的服務。
- 雙擊該服務,打開其屬性窗口。
- 檢查 “啟動類型”:將其設置為 “自動(延遲啟動)” 或 “自動”。
- 查看 “服務狀態(tài)”:如果顯示“已停止”,請點擊 “啟動” 按鈕。
- 點擊 “應用” 和 “確定” 保存設置。
第二步:通過控制面板檢查并啟用防火墻(輔助步驟)
有時僅啟動服務可能不夠,還需確保防火墻功能本身已開啟。
- 進入 “控制面板” -> “系統(tǒng)和安全” -> “Windows 防火墻”。
- 在左側面板點擊 “打開或關閉Windows防火墻”。
- 確保為您的當前網(wǎng)絡位置(家庭/工作網(wǎng)絡和公用網(wǎng)絡)都選擇了 “啟用Windows防火墻”。
- 點擊 “確定”。
第三步:創(chuàng)建防火墻例外規(guī)則(關鍵步驟)
啟動服務后,系統(tǒng)通常會自動為文件和打印機共享創(chuàng)建規(guī)則。但如果問題依舊,可以手動驗證或創(chuàng)建規(guī)則:
- 在Windows防火墻界面,點擊左側的 “允許程序或功能通過Windows防火墻”。
- 在彈出的列表中,找到 “文件和打印機共享”。
- 確保它對應的復選框已被勾選(對于家庭/工作網(wǎng)絡和公用網(wǎng)絡,根據(jù)您的共享環(huán)境選擇)。如果未被勾選,請勾選它,然后點擊 “確定”。
第四步:重新配置打印機共享
完成上述服務設置后,需要重新執(zhí)行共享操作:
- 回到 “控制面板” -> “硬件和聲音” -> “設備和打印機”。
- 右鍵點擊您想要共享的打印機,選擇 “打印機屬性”。
- 切換到 “共享” 選項卡。
- 勾選 “共享這臺打印機”,并為其設置一個簡短的共享名。
- 點擊 “應用” -> “確定”。
第五步:在其他計算機上測試訪問
在局域網(wǎng)內的另一臺計算機上:
- 打開“運行”對話框(Win + R),輸入 “\\[共享打印機的主機名或IP地址]” (例如:\\PC-01 或 \\192.168.1.100)。
- 按回車后,應該能看到共享的打印機圖標。
- 雙擊打印機圖標,按照提示安裝驅動程序即可完成網(wǎng)絡打印機添加。
高級故障排除(如果上述步驟無效)
- 檢查依賴服務:確保“Windows Firewall”服務所依賴的服務(如“Base Filtering Engine”、“Network Store Interface Service”等)也處于運行狀態(tài)。
- 使用系統(tǒng)文件檢查器:以管理員身份運行命令提示符,輸入 “sfc /scannow” 并回車,掃描并修復可能受損的系統(tǒng)文件。
- 組策略檢查(適用于專業(yè)版/旗艦版):運行 “gpedit.msc”,導航至“計算機配置”->“管理模板”->“網(wǎng)絡”->“網(wǎng)絡連接”->“Windows防火墻”,確保沒有策略強制關閉了防火墻。
###
錯誤0x000006d9的解決核心是確保 Windows防火墻服務及其相關功能正常運行。絕大多數(shù)情況下,通過手動啟動該服務并確保“文件和打印機共享”規(guī)則被啟用,問題即可迎刃而解。按照本文提供的步驟操作,您將能系統(tǒng)性地診斷并修復此問題,恢復辦公環(huán)境中高效的打印機共享。